
Prim算法
Prim算法是一种用于构造最小生成树(Minimum Spanning Tree,MST)的贪心算法。在给定一个加权无向连通图的情况下,最小生成树是图的一个子图,它连接了所有的顶点而不形成任何循环,并且具有可能的最小的边权重总和。
Prim算法的工作原理是从图中的任一顶点开始,逐渐长大覆盖整个图,每一步都添加最小权重的边,直到所有的顶点都被覆盖。
例子:
村里面一共有 n 栋房子。我们希望通过建造水井和铺设管道来为所有房子供水。 对于每个房子 i,我们有两种可选的供水方案:一种是直接在房子内建造水井,成本为 wells[i - 1] (注意 -1 ,因为 索引从0开始 );另一种是从另一口井铺设管道引水,数组 pipes 给出了在房子间铺设管道的成本,其中每个 pipes[j] = [house1j, house2j, costj] 代表用管道将 house1j 和 house2j连接在一起的成本。连接是双向的。 请返回 为所有房子都供水的最低总成本。
Prim 算法 在加权和无向图中找到最小生成树 从一个任意顶点开始,Prim 算法通过每次添加一个顶点到树中增长最小生成树。 顶点的选择基于贪婪策略,即添加新的顶点会产生最小的成本。

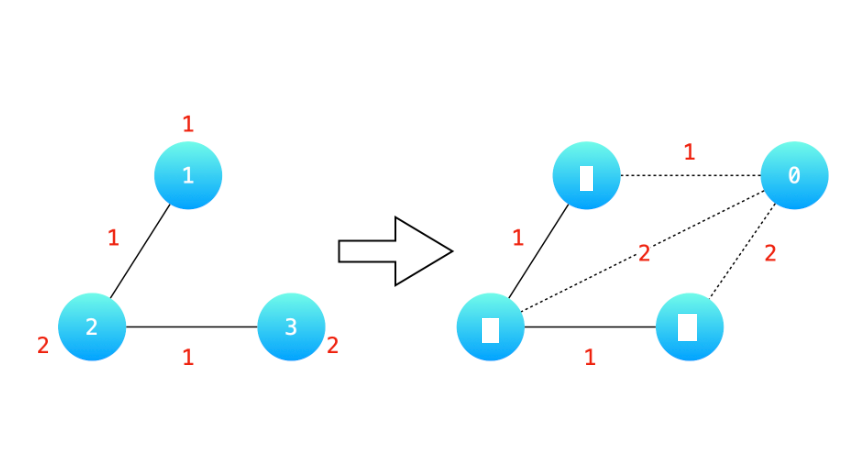
本题与建立最小生成树的差别:房子可以自己打水井。
通过添加节点0为虚拟水井,可以将房子自己打水井转换成和节点0之间建立连边:
需要用到:PriorityQueue 最小堆, List<List<Pair<Integer, Integer»> 邻接表表示图, HashSet记录已加入生成树的节点。
class Solution {
public int minCostToSupplyWater(int n, int[] wells, int[][] pipes) {
PriorityQueue<Pair<Integer, Integer>> minHeap = new PriorityQueue<>(n, (a,b) -> (a.getKey() - b.getKey()));
// key: 连接到树的成本 value: 房子的编号
List<List<Pair<Integer, Integer>>> graph = new ArrayList<>();
for (int i = 0; i < n + 1; i++) {
graph.add(new ArrayList<Pair<Integer, Integer>>());
}
// 0 号索引 虚拟水井,将 house 本身挖水井转换成和 0 号水井建立连接的边
for (int i = 0; i < n; i++) {
graph.get(0).add(new Pair<>(wells[i], i + 1));
minHeap.add(new Pair<>(wells[i], i + 1));
}
for (int i = 0; i < pipes.length; i++) {
int house1 = pipes[i][0];
int house2 = pipes[i][1];
int cost = pipes[i][2];
graph.get(house1).add(new Pair<Integer, Integer>(cost, house2));
graph.get(house2).add(new Pair<Integer, Integer>(cost, house1));
}
Set<Integer> connected = new HashSet<>();
connected.add(0);
int totalCost = 0;
while (connected.size() < n + 1) {
Pair<Integer, Integer> edge = minHeap.poll();
int cost = edge.getKey();
int house = edge.getValue();
if (connected.contains(house)) continue;
connected.add(house);
totalCost += cost;
for (Pair<Integer, Integer> p : graph.get(house)) {
if (!connected.contains(p.getValue()))
minHeap.add(p);
}
}
return totalCost;
}
}
复杂度分析:
时间复杂度: \(O((N+M)⋅log(N+M))\)
构建图,我们迭代了输入的房屋和管道,这需要 \(O(N + M)\) 的时间。 当构建 MST 时,在最坏的情况下,我们可能需要迭代图中的所有边,总数为 \(N + M\) 。 对于每个边,它最多进入和退出堆数据结构一次。把边放入堆中 (push 操作) 需要 \(log(N+M)\) 的时间,而退出边 ( pop 操作) 需要一个常数时间。 因此,MST 构建过程的时间复杂度是 \(O((N+M)⋅log(N+M))\)。 总的来说,算法的总体时间复杂度是 $$O((N+M)⋅log(N+M)).$$
参考:力扣(LeetCode)
Kruskal算法
Kruskal算法是一种用于在加权图中找到最小生成树(Minimum Spanning Tree, MST)的算法。它适用于边的权重各不相同的连通图。Kruskal算法是基于贪心策略实现的,其主要思想是按照边的权重顺序(从小到大)处理每条边,并在不形成环的前提下逐步添加到最小生成树中。
Kruskal算法的步骤:
- 排序所有边: 将图中所有的边按照权重从小到大排序。可以使用任何有效的排序算法来完成这一步,如归并排序、快速排序等。
- 初始化并查集: 使用并查集数据结构来维护和查询顶点间的连通性。初始时,每个顶点都处于不同的集合中。
- 选择最小边: 从排序后的边列表中选择最小的边。检查这条边连接的两个顶点是否已经在同一个集合中(即检查是否会形成环):
- 如果不会形成环(即两个顶点不在同一个集合中),则将这条边添加到最小生成树中,并使用并查集合并这两个顶点所在的集合。
- 如果会形成环,则丢弃这条边,不将其加入最小生成树。
- 重复选择过程: 重复第3步,直到添加了 V−1 条边到最小生成树中,其中 V 是图中顶点的数量。在连通图中,最小生成树恰好包含 V-1 条边。
- 完成构建: 当添加了足够的边(V-1 条)后,算法完成,此时构建的就是整个图的最小生成树。
class Solution {
private static final int MAX_N = 10005;
private int[] f = new int[MAX_N];
private void init() {
for (int i = 0; i < MAX_N; ++i) {
f[i] = i;
}
}
private int find(int x) {
return x == f[x] ? x : (f[x] = find(f[x]));
}
private void merge(int u, int v) {
f[find(u)] = find(v);
}
public int minCostToSupplyWater(int n, int[] wells, int[][] pipes) {
init();
List<int[]> edges = new ArrayList<>();
for (int i = 1; i <= n; ++i) {
edges.add(new int[] { 0, i, wells[i - 1] });
}
for (int[] pipe : pipes) {
edges.add(pipe);
}
edges.sort(Comparator.comparingInt(a -> a[2]));
int ret = 0;
for (int[] edge : edges) {
if (find(edge[0]) != find(edge[1])) {
merge(edge[0], edge[1]);
ret += edge[2];
}
}
return ret;
}
}
Dijkstra算法
用于解决图中的单源最短路径问题。这个算法可以找到一个顶点到图中其他所有顶点的最短路径。它适用于包含非负权重边的图。
初始化:
- 选择图中的一个源点。
- 初始化一个距离数组,其中源点到自己的距离设为0,到其他所有点的距离设为无穷大(或一个非常大的数)。
- 使用一个优先队列(最小堆)来存储所有顶点的距离,优先队列按距离排序。
处理每个顶点:
- 从优先队列中取出当前距离最短的顶点(初始时是源点)。
- 对于这个顶点的每个邻接顶点,检查通过当前顶点到邻接顶点的路径是否比已知的路径更短。如果更短,则更新邻接顶点的最短路径值,并在优先队列中更新这个顶点的位置。
重复执行:
- 重复步骤2直到优先队列为空,即所有可达顶点的最短路径都已找到。
完成:
- 算法完成后,距离数组中存储的就是源点到图中每个顶点的最短距离
如果使用数组,时间复杂度是 O(V^2),其中 V 是顶点数。
如果使用二叉堆作为优先队列,时间复杂度可以优化到 O((V+E) \log V),其中 E 是边的数量。
例题:
// leetcode743. 网络延迟时间:
// ┌─┐ 1 ┌─┐
// │2├───►│3│
// └┬┘ └┬┘
// │ │
// 1 │ │ 1
// ▼ ▼
// ┌─┐ ┌─┐
// │1│ │4│
// └─┘ └─┘
// 从2传递到所有节点,需要的时间:2
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
class Solution {
public int networkDelayTime(int[][] times, int n, int k) {
// build the graph
List<int[]>[] graph = new List[n + 1];
for (int i = 0; i <= n; i++) {
graph[i] = new ArrayList<int[]>();
}
int[] delays = new int[n + 1];
Arrays.fill(delays, Integer.MAX_VALUE);
delays[k] = 0;
// 注意数据初始化
for (int[] time : times) {
int start = time[0];
int end = time[1];
int latency = time[2];
graph[start].add(new int[]{end, latency});
}
//利用pq就不用维护visited数组了,直接bfs
PriorityQueue<int[]> pq = new PriorityQueue<int[]>((a,b) -> {return a[1] - b[1];});
pq.offer(new int[]{k, 0});
while (!pq.isEmpty()) {
int[] cur = pq.poll();
int cur_id = cur[0];
int cur_dist = cur[1];
if (cur_dist > delays[cur_id]) continue;
for (int[] neighbor : graph[cur_id]) {
int delay_to_next = neighbor[1] + delays[cur_id];
if (delay_to_next < delays[neighbor[0]]) {
delays[neighbor[0]] = delay_to_next;
pq.offer(new int[]{neighbor[0], delay_to_next});
}
}
}
int temp = Integer.MIN_VALUE;
for (int i = 1; i <= n; i++) {
if (delays[i] == Integer.MAX_VALUE) {
return -1;
}
temp = Math.max(temp, delays[i]);
}
return temp;
}
}